The Case for Pull Rebase
The standard git pull command doesn’t play well with the Trunk-based development workflow. Fortunately, there’s a somewhat obscure way to make things right.
I’m going to make a bold generalization here and say that most development teams would rather work on a single shared branch.
I’m putting the emphasis on shared because, while there may well be other kinds of branches being worked on at any given time (feature branches and Pull Request branches come to mind) there’s still only one main branch everyone commits to. The other branches are often focused on one specific task, so, naturally, they exist for a limited period of time.1
When I say single shared branch, I also mean a long-running branch, one that spans over the entire lifetime of the project.
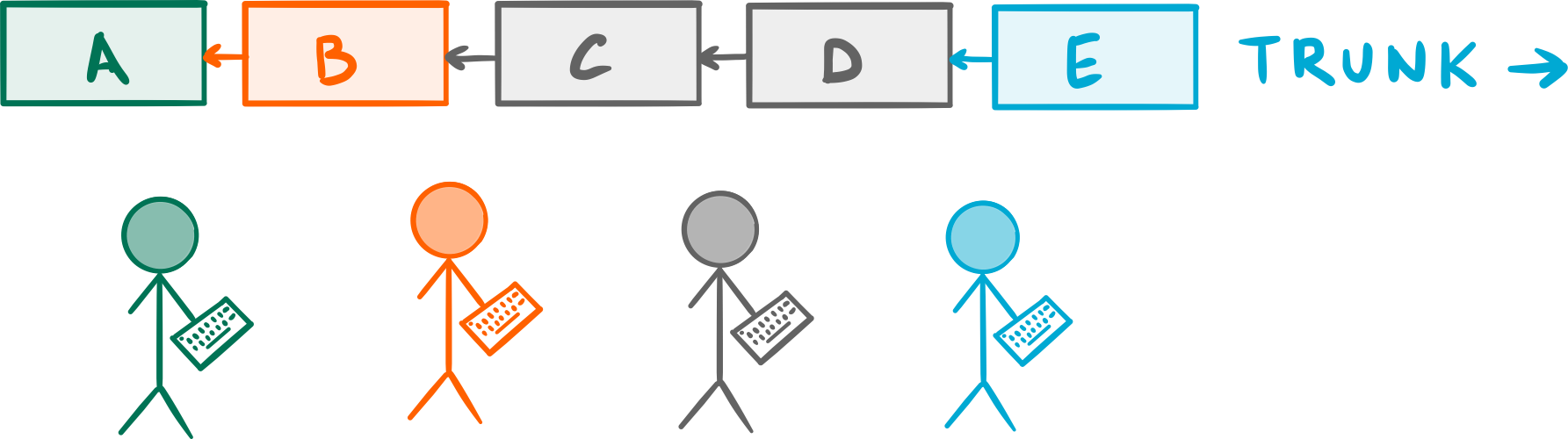 Everyone commits their work on a single shared branch, often called
Everyone commits their work on a single shared branch, often called Trunk.
This style of collaboration is called Trunk-Based Development or Mainline development and is, in my experience, the most common workflow you see around. That’s no coincidence: it’s also the oldest style of development collaboration known to mankind (dating all the way back to the dawn of version control systems) and one most programmers feel comfortable with. After all, there’s ever only one version of the code to worry about.
As much as I love Git’s beautiful branching model, there’s no denying that sticking with the Mainline development workflow for as long as possible is often the smart thing to do in a project. In fact, that’s what the vast majority of open source projects do.2
Having a single long-running shared branch isn’t the problem here; the default behaviour of the git pull command is. Here’s why.
Anatomy of a Git Pull
If you aren’t familiar with Git’s inner workings, it might come as a surprise to know that git pull isn’t actually a core command per se,3 but rather a combination of two other commands: git fetch and git merge; the former downloads any missing commits from a remote repository, while the latter merges them into your current branch.4
Imagine you have a repository whose history looks like this:
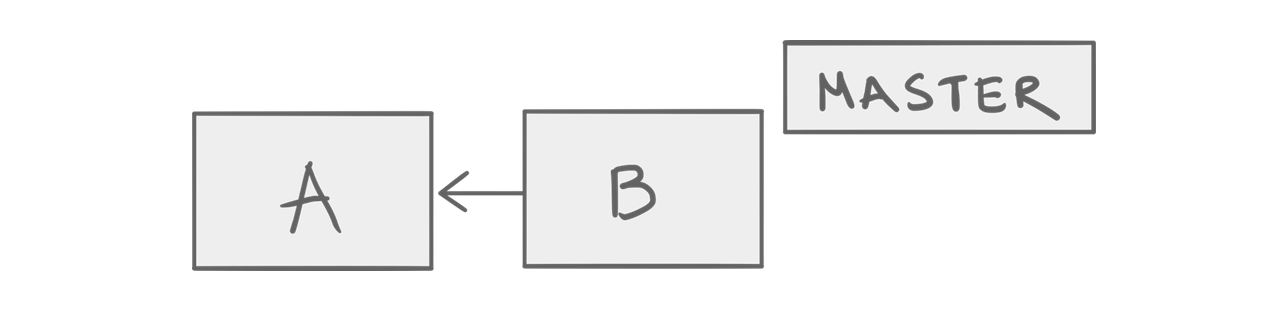 A simple repo.
A simple repo.
Now, let’s say that you make a new commit C on master. Meanwhile, someone else on your team commits D on their own version of master; now, here’s the catch: they manage to push their commit to the project’s central shared repository before you.
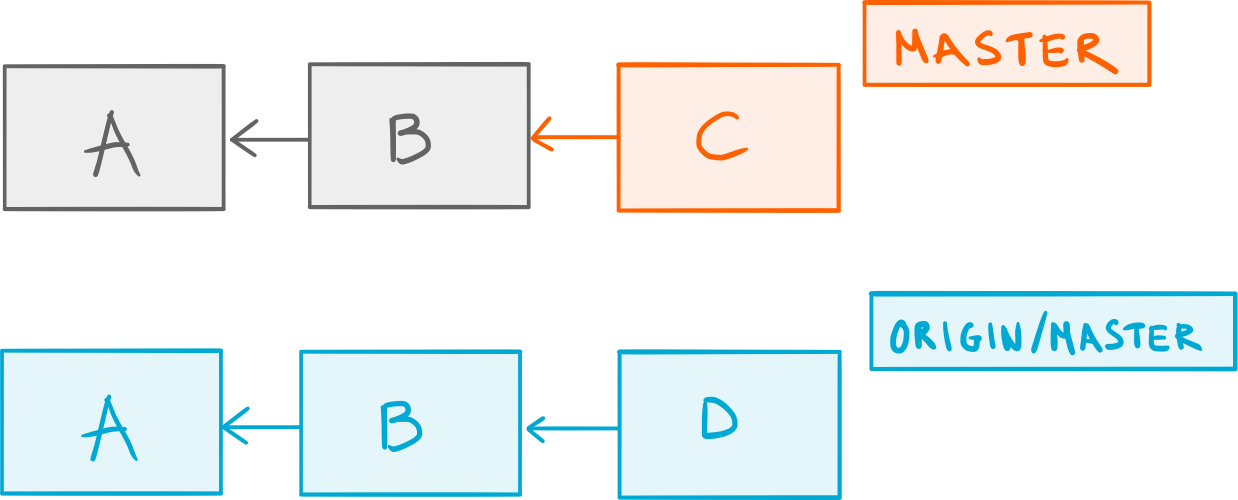 You commit
You commit C, someone else pushes D.
Unaware of that, you try to push your brand new commit C but are bluntly denied — Git lets you know that B no longer is the latest commit in the remote master branch:
! [rejected] master -> master (non-fast-forward)
error: failed to push some refs to '<remote-url>'
hint: Updates were rejected because the tip of your current branch is behind
hint: its remote counterpart. Integrate the remote changes (e.g.
hint: 'git pull ...') before pushing again.
You shrug and run git pull to get the latest commits. Now, keep in mind that git pull is actually git fetch followed by git merge, so here’s what you end up with:
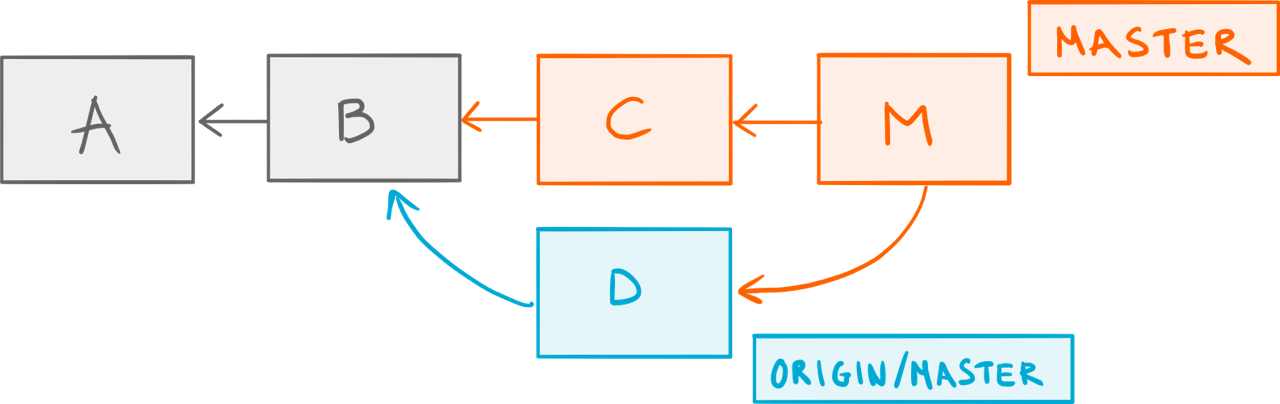 The result of a regular pull.
The result of a regular pull.
Git fetched the new commit D from the remote repository, updated your local reference to the remote master branch origin/master5 and merged that into your local master, thus creating the merge commit M.
You’re now finally ready to push your beloved commit C, along with commit M.
Merge Clutter
At this point, you might think so what, this is just business as usual, and you’d be right — after all, this is what happens when you invoke the standard pull command without any fancy options.
However, consider the effect this has on your repo over time:
 Cluttered history.
Cluttered history.
This is how history looks like in a project who uses Git together with the Trunk-based development workflow (which, as we established, is pretty common). You see all those merge commits cluttering the mainline? The only reason they exist is because someone on the team happened to push their commits before someone else.
In other words, when everyone commits to a single shared branch, the standard
git pullcommand is going to clutter your history with a bunch of merge commits, simply due to the asynchronous nature of collaboration.
A merge commit should represent a significative event, namely the point in time in which two different lines of history came together: a topic branch merged into a long-running branch (like a pull request), or a long-running branch merged into another (like a release) just to give you an example. The merge commits created by git pull, on the other hand, don’t represent anything — they are an artificial side-effect.
Pull Rebase
Fortunately, it doesn’t have to be that way. Here’s a different approach.
We said that git pull is actually two separate operations: git fetch followed by git merge. Well, it turns out that if we pass the -r (–rebase) option to git pull, we can replace that git merge with git rebase. I know, a fine example of Git’s syntax at its best, right?
Let’s go back to our previous example right before we did git pull.
Back to square one.
This time, we do git pull -r instead and look at what happens:
 The result of a pull rebase.
The result of a pull rebase.
Git still fetched commit D but instead of merging origin/master into our local master, it rebased C on top of origin/master, thus giving us a linear history.
Now, if everyone on the team was doing git pull --rebase by default, we wouldn’t have any of those artificial merge commits. That’s a win in my book, but we are not done yet.
Keeping The True Merges
There is one more scenario we need to consider: what if you have a local merge commit that you do want to push to the remote — is git pull -r going to keep it?
Unfortunately, the answer is no.
Let’s start once again with our previous example, only this time we have a legitimate merge commit N that we want to share with the world:
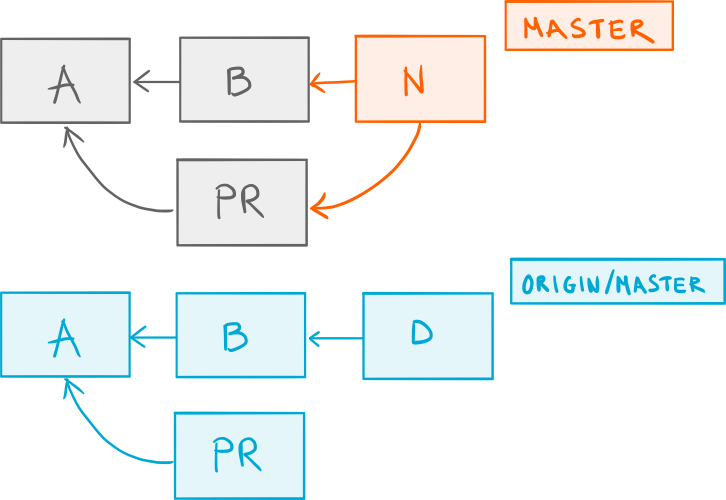 A locally merged pull request branch containing the
A locally merged pull request branch containing the PR commit.
Just for the sake of the argument, let’s see what would happen if we were to run the plain git pull first:
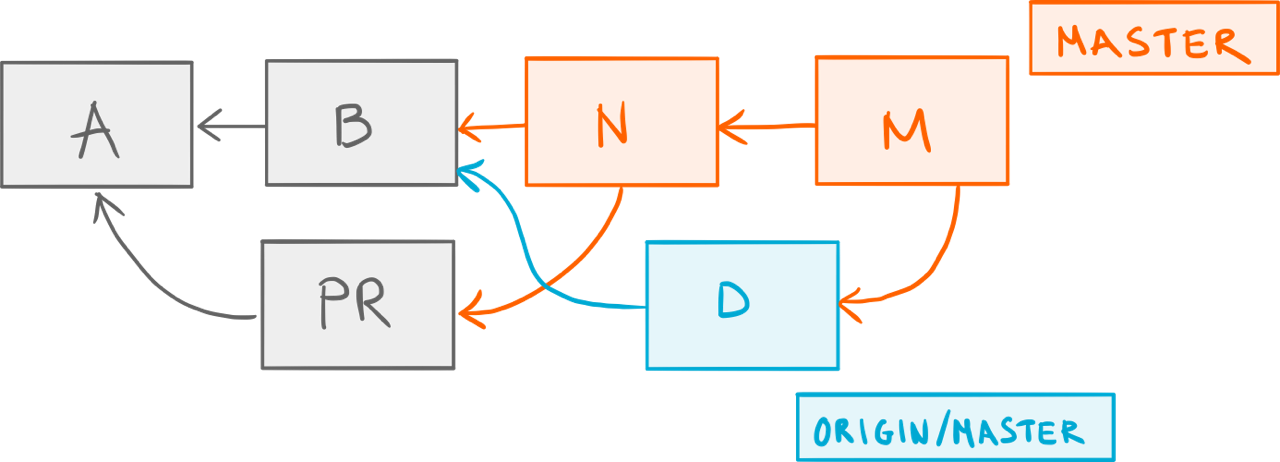 One merge too many.
One merge too many.
Double-merge! 😱 Fortunately, we know better now, so let’s run git pull -r instead:
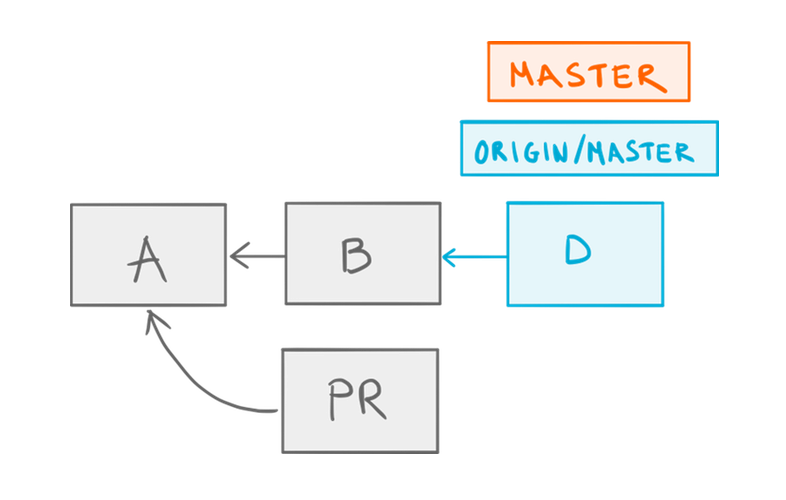 Our merge commit
Our merge commit N is gone after a pull rebase.
Wait — where did N go? The answer is git rebase removed it because, well, that’s what rebase does by default. Luckily for us, there is an option to keep the merge commits during a rebase: the --preserve-merges parameter.6
In the context of git pull, this translates to git pull --rebase=preserve. So, let’s run that instead:
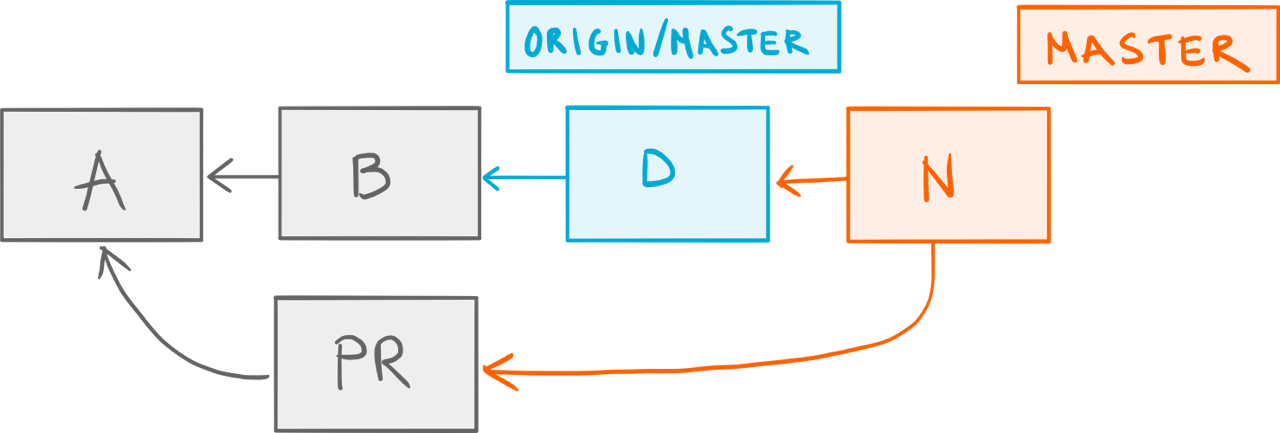 Rebased merge.
Rebased merge.
That’s more like it: our merge commit N was rebased on top of the remote origin/master branch.7
The New Default
You’d be forgiven for not remembering to invoke pull with the right combination of arguments at any given time, so let’s make it our new default, shall we? The way you tell Git to always do a pull rebase instead of a pull merge (while still keeping any local merge commits) is by setting the pull.rebase configuration option:
git config --global pull.rebase preserve
git config --global pull.rebase merges # if you're on Git 2.18 or later
Of course, you can omit the --global option if, for some reason, you only want this to apply to your current repository.
In Conclusion
The combination of using a Trunk-based development workflow with the regular git pull command leads to a history cluttered with merge commits that you don’t want. Fortunately, by simply replacing the merge part of git pull with rebase, you can enjoy a straightforward single-branch workflow without sacrificing the cleanness of your history.
If you're interested in learning other techniques like the one described in this article, you should check out my Pluralsight course Git Tips and Tricks.
-
In Git’s parlance, these are often called topic branches. ↩
-
With a twist: external (and sometimes also internal) contributors can’t commit directly to the main branch, but instead have to submit their code a dedicated Pull Request branch. This workflow has become known as the GitHub Flow. ↩
-
In fact, like many other commands in Git, it used to be a shell script. ↩
-
Where by current, I mean the branch that reflects your working copy. In technical terms, that would be the branch referenced by
HEAD. ↩ -
Git calls them tracking branches but you can think of them as bookmarks that keep track of where a branch is on a remote repository. ↩
-
There’s a interesting story behind the origin of the
--preserve-mergesoption. If you have the time, I suggest you read it. It’s all told inside of a commit message. ↩ -
A short note: the
--preserve-mergesoption has recently been replaced by a more robust implementation in the form of the--rebase-mergesoption. If you’re using Git 2.18 (Q2 2018) or later, you should use that instead by sayinggit pull --rebase=merges. ↩
Enrico Campidoglio
Hi, I'm Enrico Campidoglio. I'm a freelance programmer, trainer and mentor focusing on helping teams develop software better. I write this blog because I love sharing stories about the things I know. You can read more about me here, if you like.
 The material published on this blog
by
Enrico Campidoglio
The material published on this blog
by
Enrico Campidoglio
is licensed under a
Creative Commons Attribution 4.0 International License
.
© Enrico Campidoglio AB, 2008–2024 — built with Vim and Jekyll.